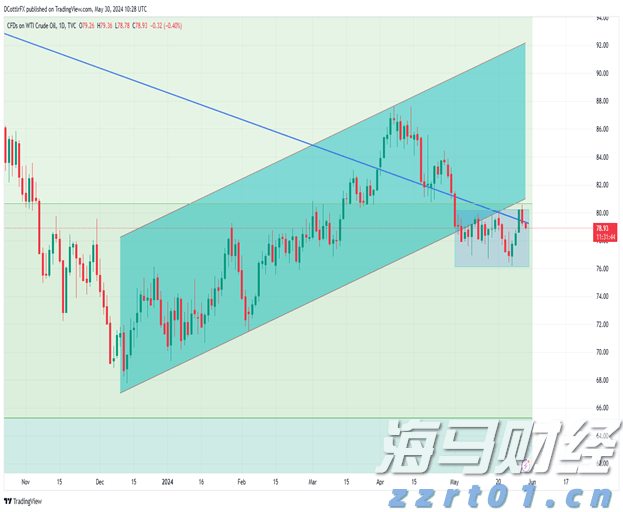
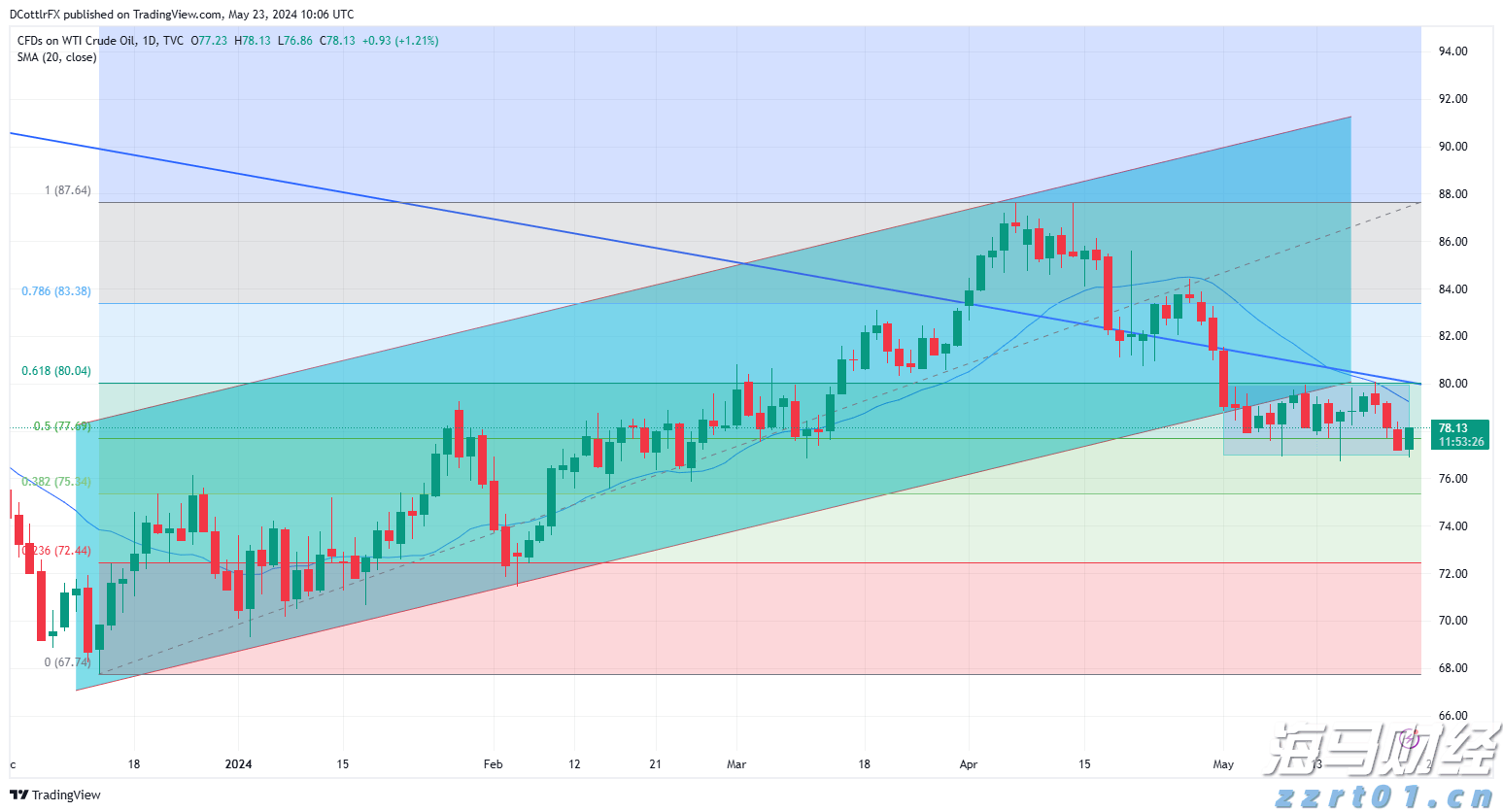
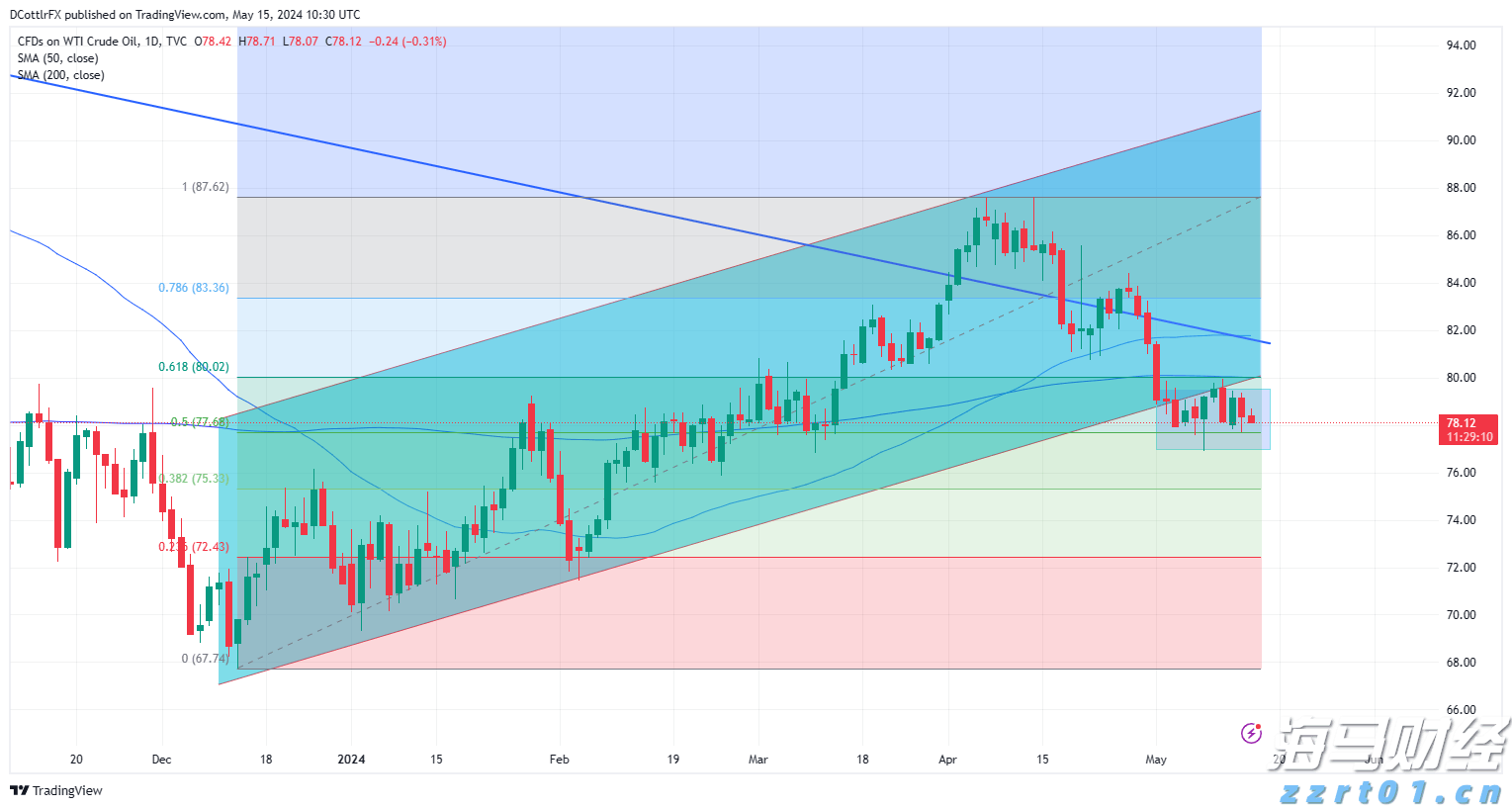
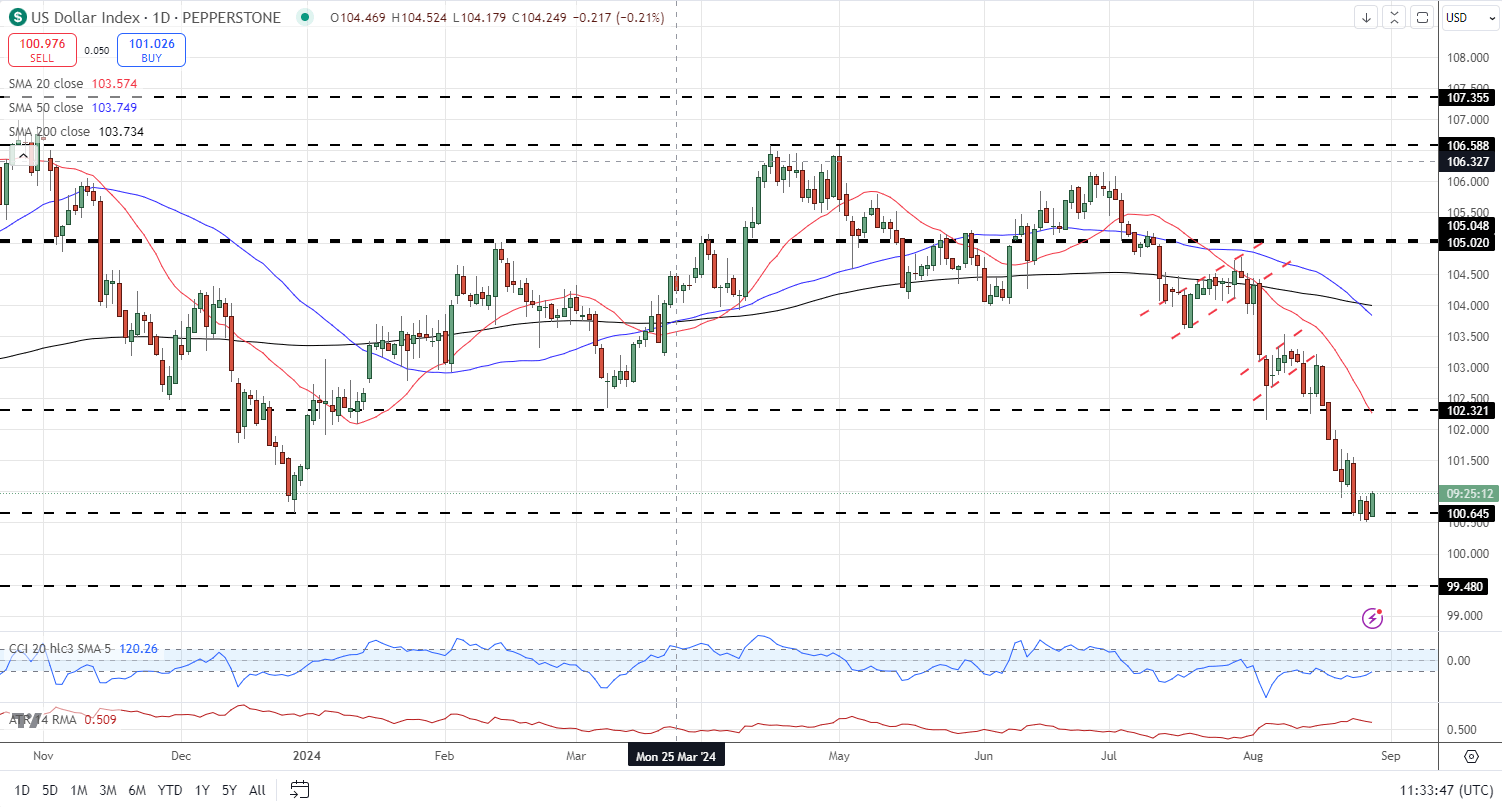
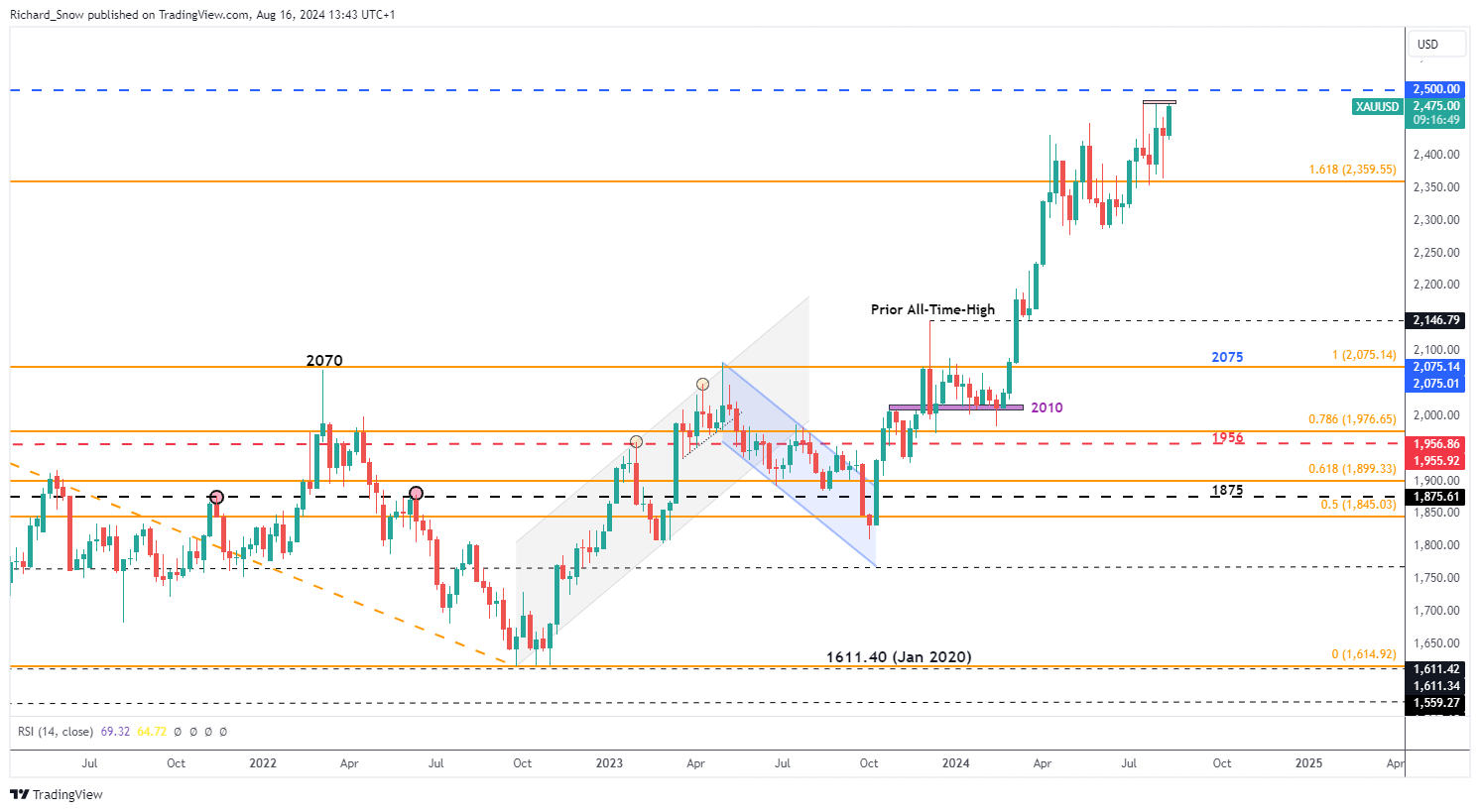
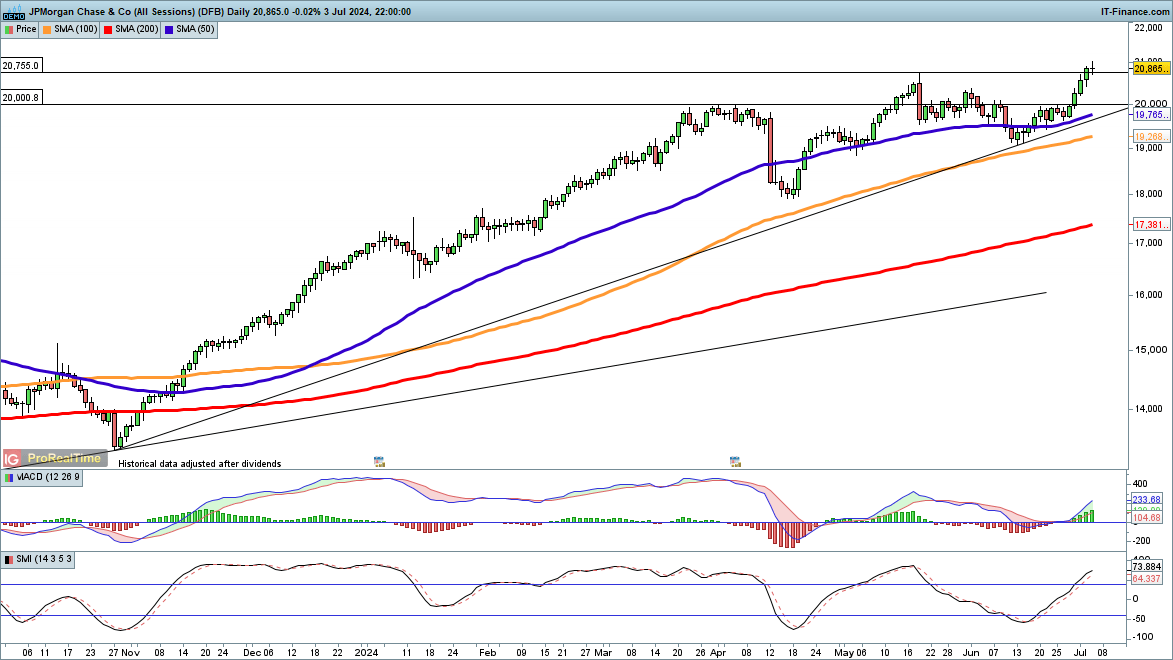
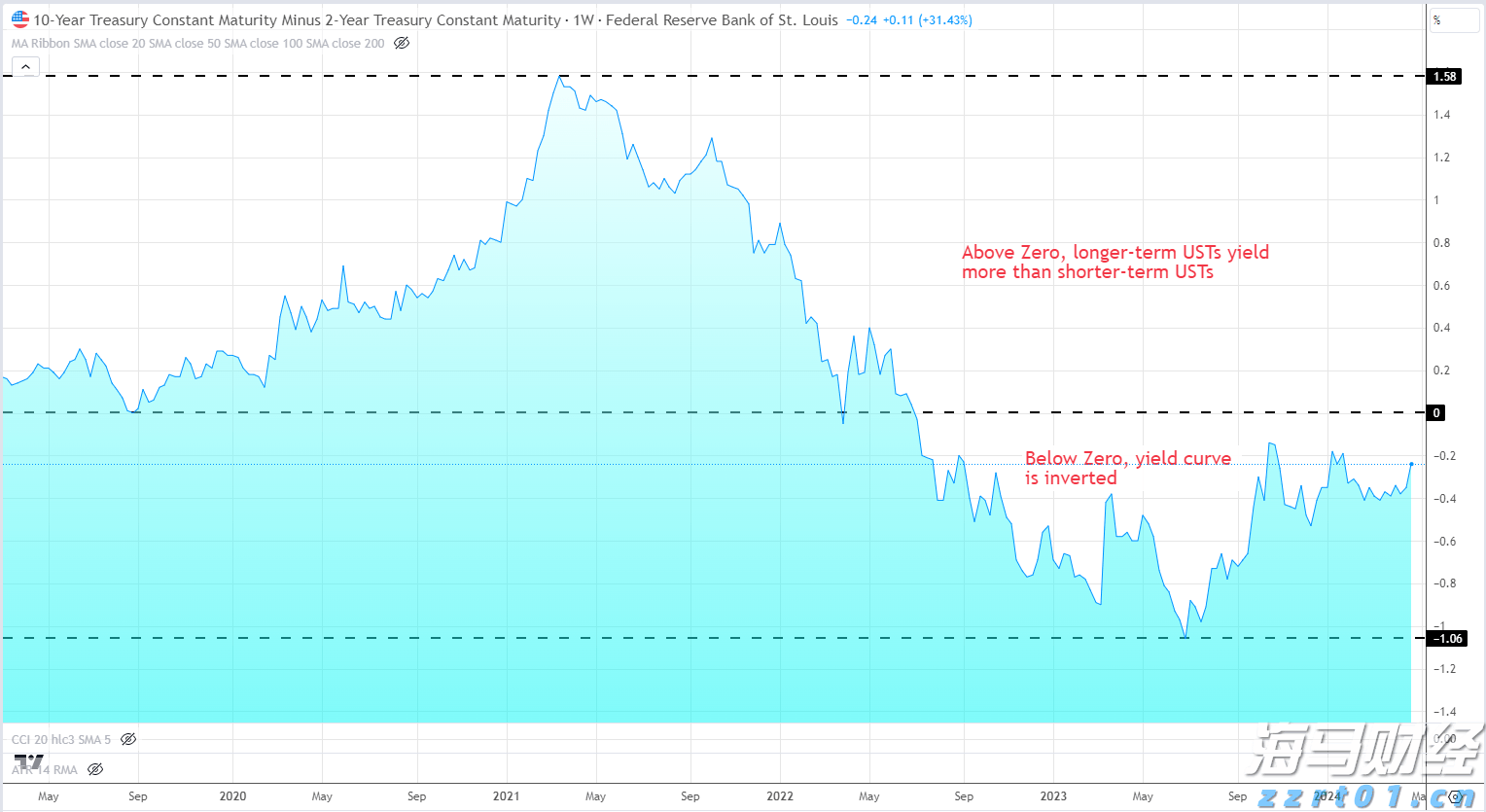
劳埃德银行集团2024年第三季度收益:数据告诉我们什么?银行巨头劳埃德银行集团报告称,税后法定利润达到了13亿英镑,展现了在复杂的经济环境中的韧性。这一业绩反映了银行在市场逆风...
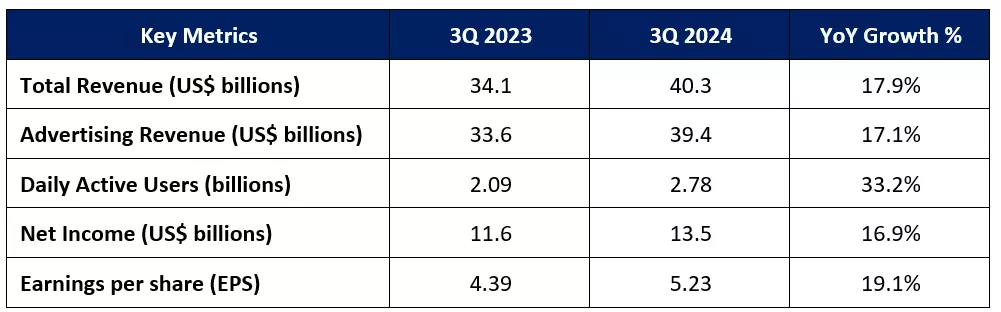
Facebook公司的第三季度盈利预览: 未来将进一步增加市Meta Platforms(原Facebook)计划在2024年10月30日美国股市收盘后发布其2024年第三季度的财...

苹果的财报公布日期及预期情况科技巨头苹果预计将公布每股调整后收益为1.593美元。收入预期为942.15亿美元。
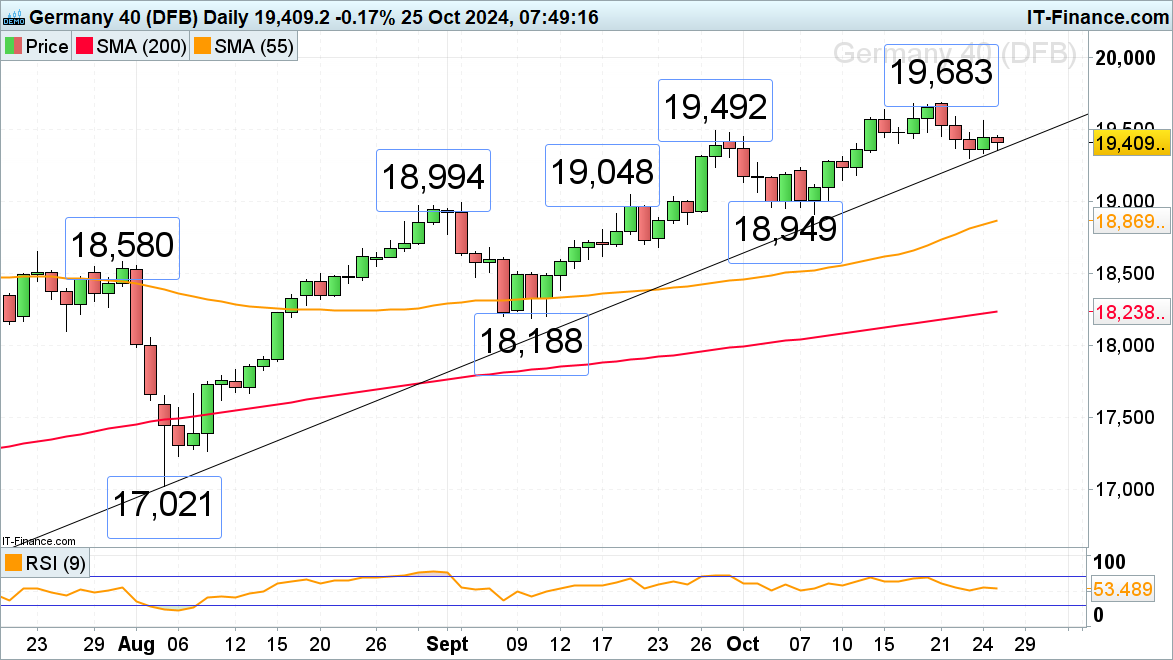
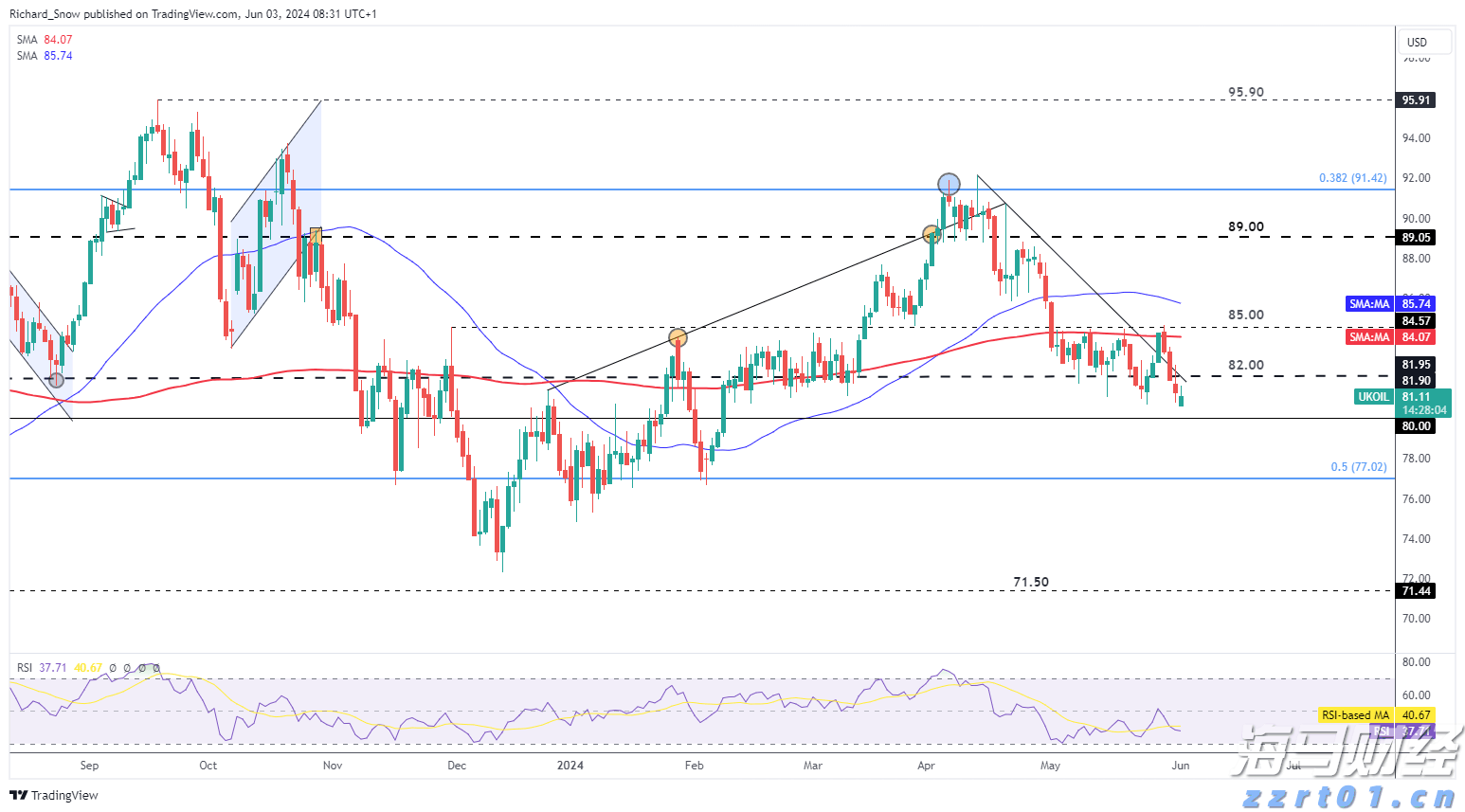
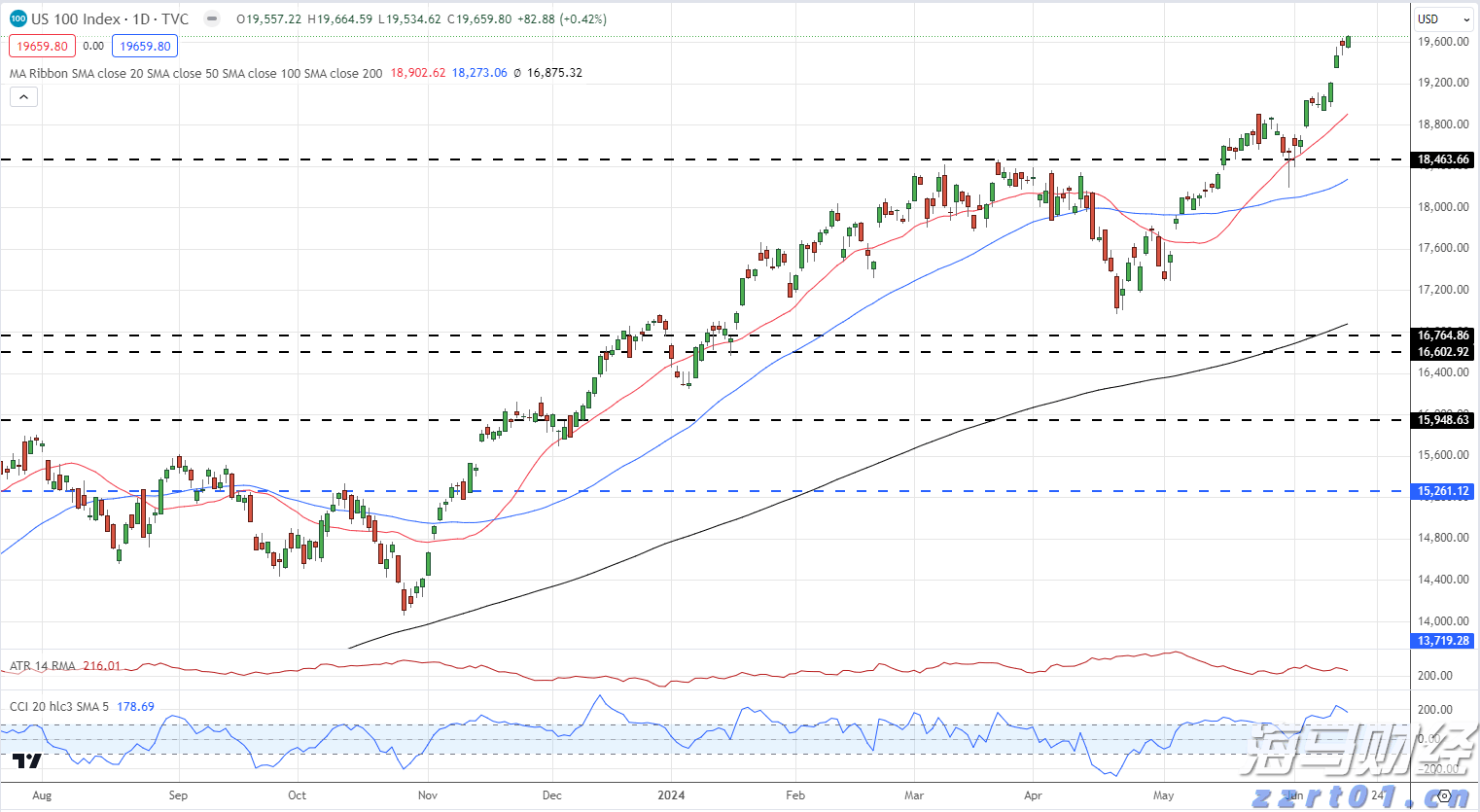
DAX 40, 道琼斯和纳斯达克 100 欧元周线走低DAX 40 从周一的最新纪录高点19,683回落,并跌破了9月底19,492的峰值,本周将迎来三个星期以来的首次周线下...
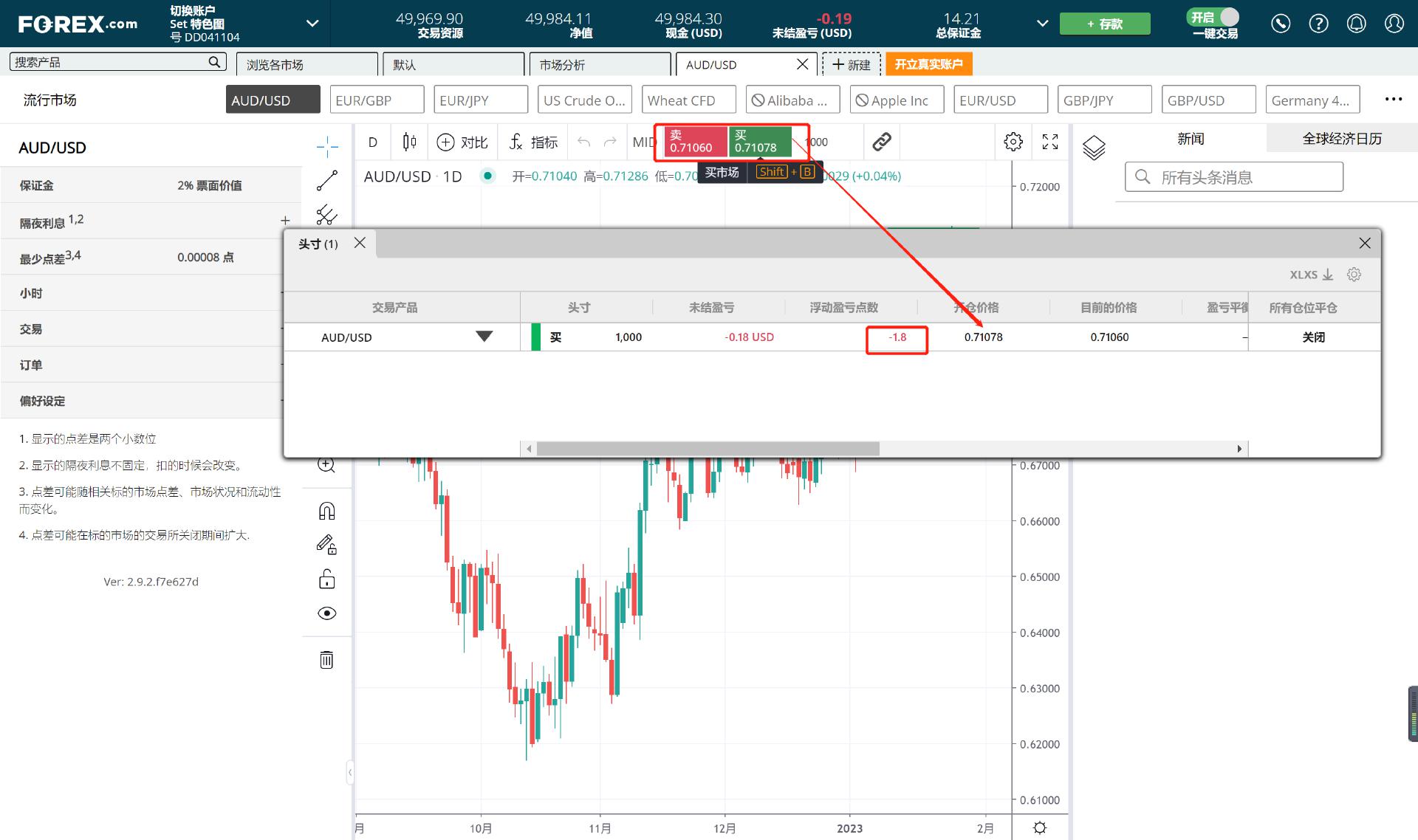
2024年最佳外汇平台列表,从稳定的交易环境、安全的资金保障到优质的客户服务。我们精选的外汇经纪商提供卓越的交易体验,助您成功开展外汇交易。
换一组